AWS NYC Taxi Lakehouse Project
by L. Mark Coty
Why this project?
I chose this project to practice building a realistic, production-style data pipeline without relying on front-end development. The NYC TLC dataset is large enough to surface real data engineering concerns—schema consistency, partitioning, dimensional modeling, and data quality—while still being publicly available and well documented. This project allowed me to design an end-to-end Bronze → Silver → Gold lakehouse on AWS, using the same tools and patterns commonly found in real-world analytics pipelines.
GitHub repository here.
End-to-End Pipeline Summary::
Ingested NYC TLC Yellow Taxi trip data (≈3.3M rows/month) and taxi zone lookup data into an Amazon S3 Bronze layer using a partitioned folder structure.
Built AWS Glue (Spark) ETL jobs to clean and standardize trip data, derive trip-level metrics, and write optimized Parquet datasets to the Silver layer.
Created a dimensional model with a curated trip fact table and a taxi zone dimension to support geographic analytics.
Registered Silver datasets in the AWS Glue Data Catalog and queried them using Amazon Athena.
Generated analytics-ready Gold marts using Athena CTAS, including revenue by pickup borough, borough-to-borough trip flows, and top pickup zones by month.
Implemented partitioning (year, month) and Parquet storage to reduce Athena scan costs and improve query performance.
Published a monthly data quality snapshot capturing row counts, referential integrity metrics, and key trip statistics.
Documented the pipeline architecture, data model, and reproducible runbook in a GitHub repository.
Below is a diagram of the pipeline: (See GitHub for clearer view.)
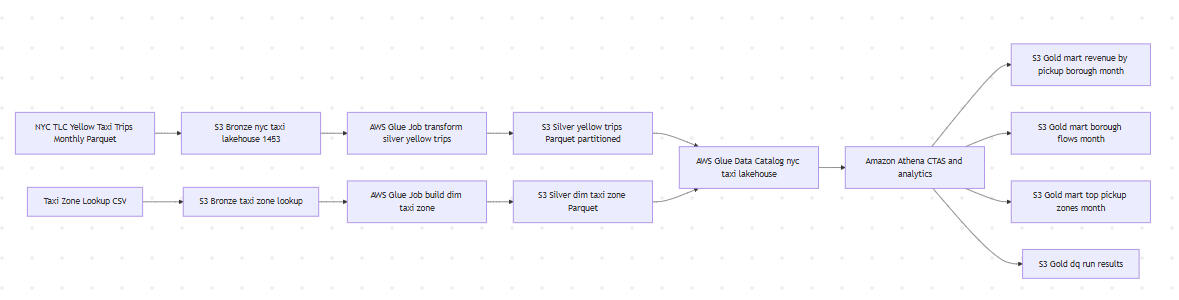
The Content and Nature of the Data:
The Bronze dataset consists of monthly NYC Taxi & Limousine Commission (TLC) Yellow Taxi trip records published as Parquet files. Each record represents a single taxi trip and includes pickup and dropoff timestamps, trip distance, fare and surcharge components, payment type, and location identifiers for pickup and dropoff zones. The data is provided at city scale, with millions of records per month, and reflects real-world operational variability such as missing values and schema changes over time. A supplemental taxi zone lookup table in CSV format maps location identifiers to boroughs and zone names for geographic enrichment.
The Silver layer contains cleaned and standardized NYC Yellow Taxi trip data stored as partitioned Parquet files. Raw timestamps and numeric fields are normalized, and derived metrics such as trip duration in seconds and trip date are added to support downstream analytics. Records with invalid timestamps, extreme durations, negative fares, or unrealistic distances are filtered to improve data quality. The dataset is partitioned by year and month to optimize query performance and cost in Amazon Athena.
The Gold layer contains analytics-ready tables designed for direct querying and reporting. These marts are created using Amazon Athena CTAS queries that join the curated trip fact data with the taxi zone dimension to provide geographic context. The marts include monthly revenue by pickup borough, borough-to-borough trip flows, and top pickup zones by trip volume. All Gold tables are stored as Parquet files and partitioned by year and month to support efficient filtering and cost-effective queries. A dedicated data quality mart captures monthly pipeline health metrics, including row counts, referential integrity checks, and key trip statistics.